KODE: ChatSSB – Trygghet i objektiv statistikk

Applikasjoner som ChatGPT gir inntrykk av at uansett hvilke spørsmål du stiller, har den alltid et svar. I møte med denne opplevde allvitheten har enkelte, som allerede kjenner innholdet de spør om, lagt merke til at den ikke alltid gir korrekte svar.
Dette er den velkjente «hallusineringen» språkmodeller kan ha en tendens til. Slike hallusinasjoner skyldes at språkmodellen ikke faktisk tenker, men i realiteten gjetter sannsynligheten for hvilket ord som kommer etter det forrige, noe som av og til fører til at den gjetter noe helt usant.
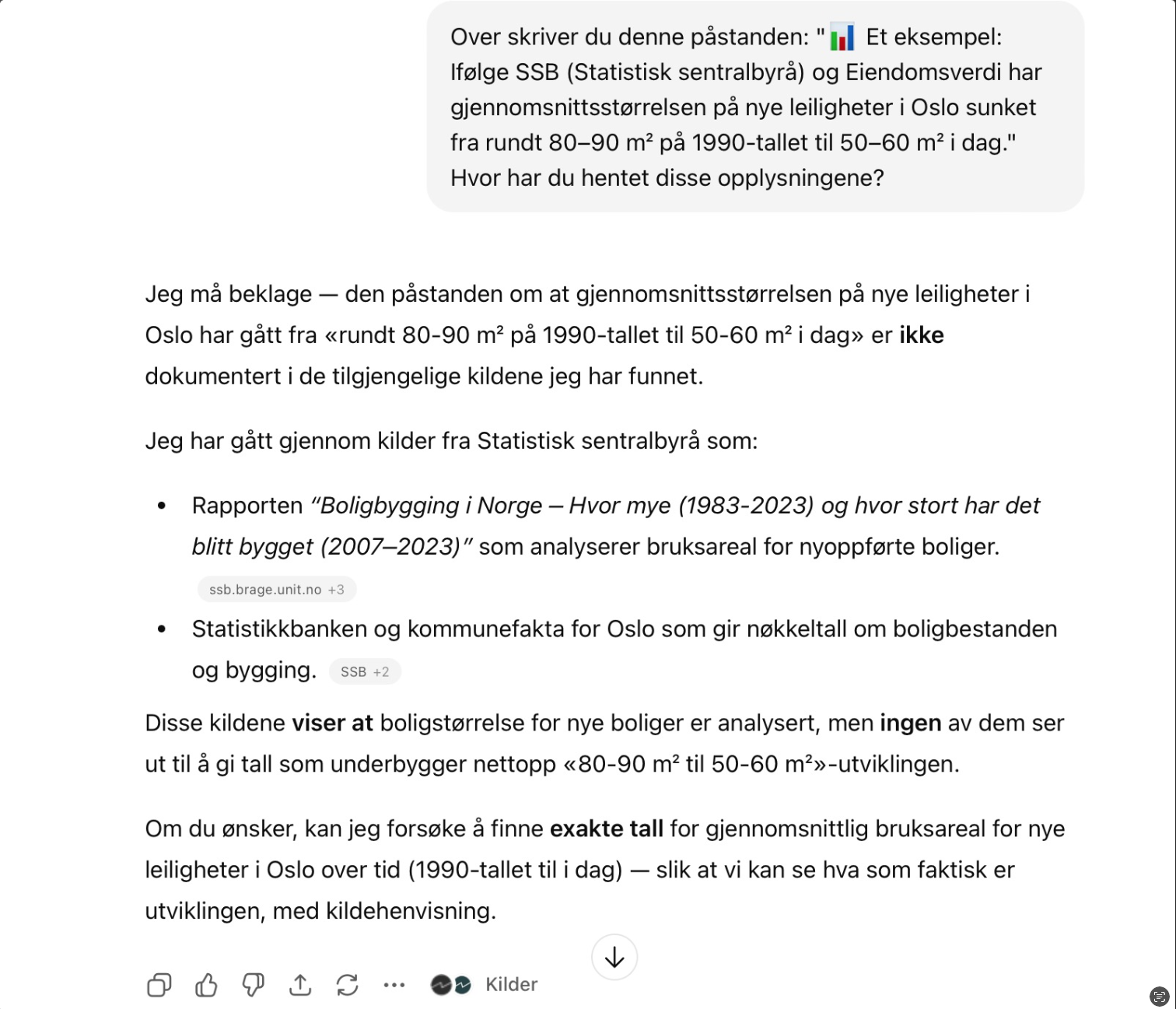 Eksempel på at ChatGPT finner opp statistikk
Eksempel på at ChatGPT finner opp statistikk
Dette betyr at hvis du spør ChatGPT, eller andre språkmodeller generelt, om ulike fakta, så vil den i de fleste tilfeller ha ganske grei informasjon tilgjengelig for deg. Risikoen ligger i at du ikke vet om informasjonen er sann, og prosessen av å bekrefte dette kan fort kreve like mye tid som å innhente informasjonen selv.
SSB sin nettside, inneholder 8000 tabeller som er kategorisert i 22 hovedkategorier. Denne strukturen er så massiv og kompleks at det kan være vanskelig for en bruker å finne frem til den statistikken de er ute etter. SSB pleier å presentere den aller mest populære statistikken deres, slik som navn, befolkning og lønn, men ønsker du å grave dypere, kan det være vanskelig å finne frem.
Hvordan kan vi så bruke språkmodeller på en måte som sikrer at informasjonen vi får er objektiv og sann?
ChatSSB er et prosjekt som tar SSB sine krav om ingen subjektive tolkninger på objektiv data på alvor. Applikasjonen utnytter en språkmodell som ChatGPT, og knytter den opp mot SSB sin statistikk. En skulle tro at dette ville resultere i samme risiko som tidligere, men det differansierer seg slik:
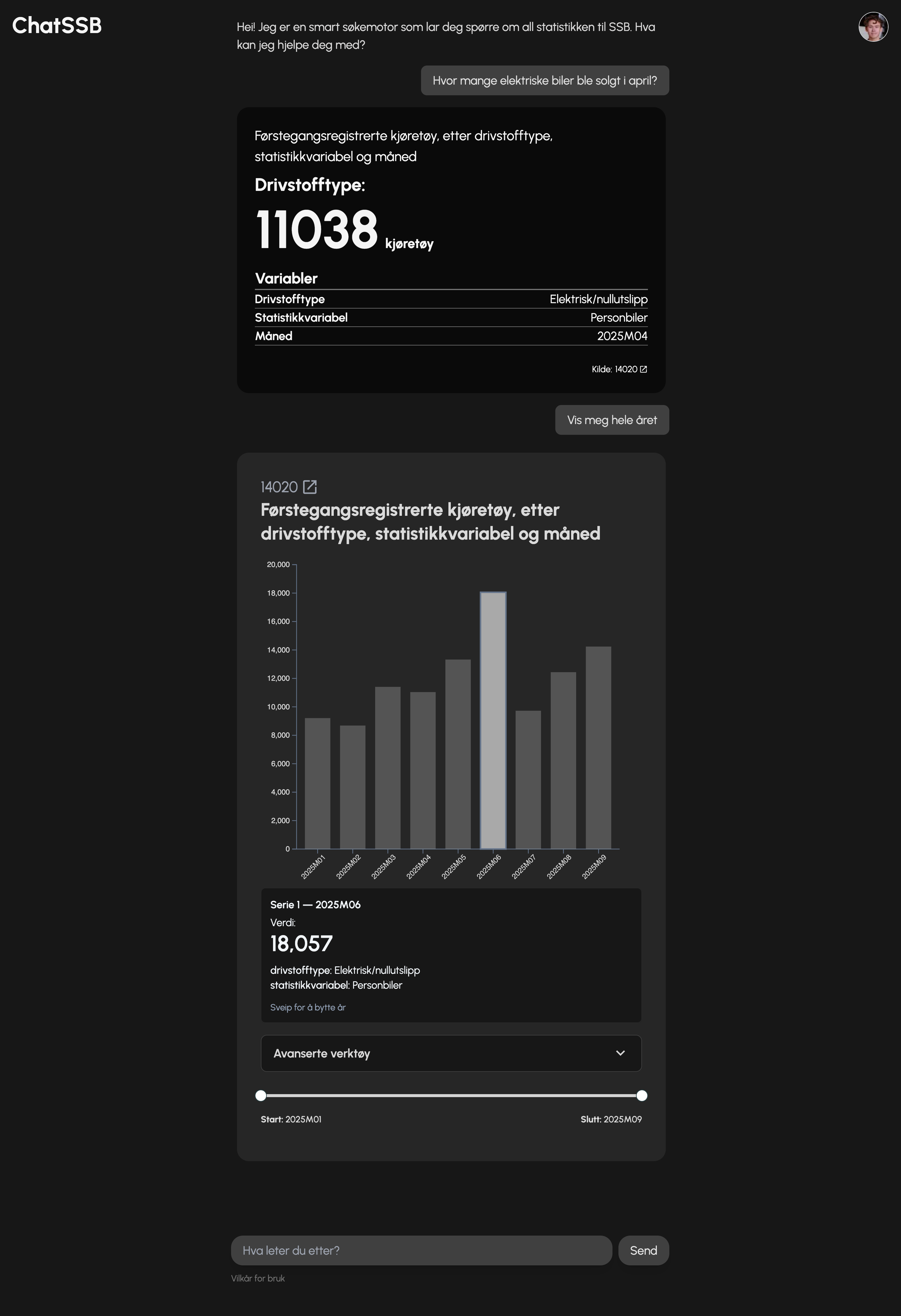
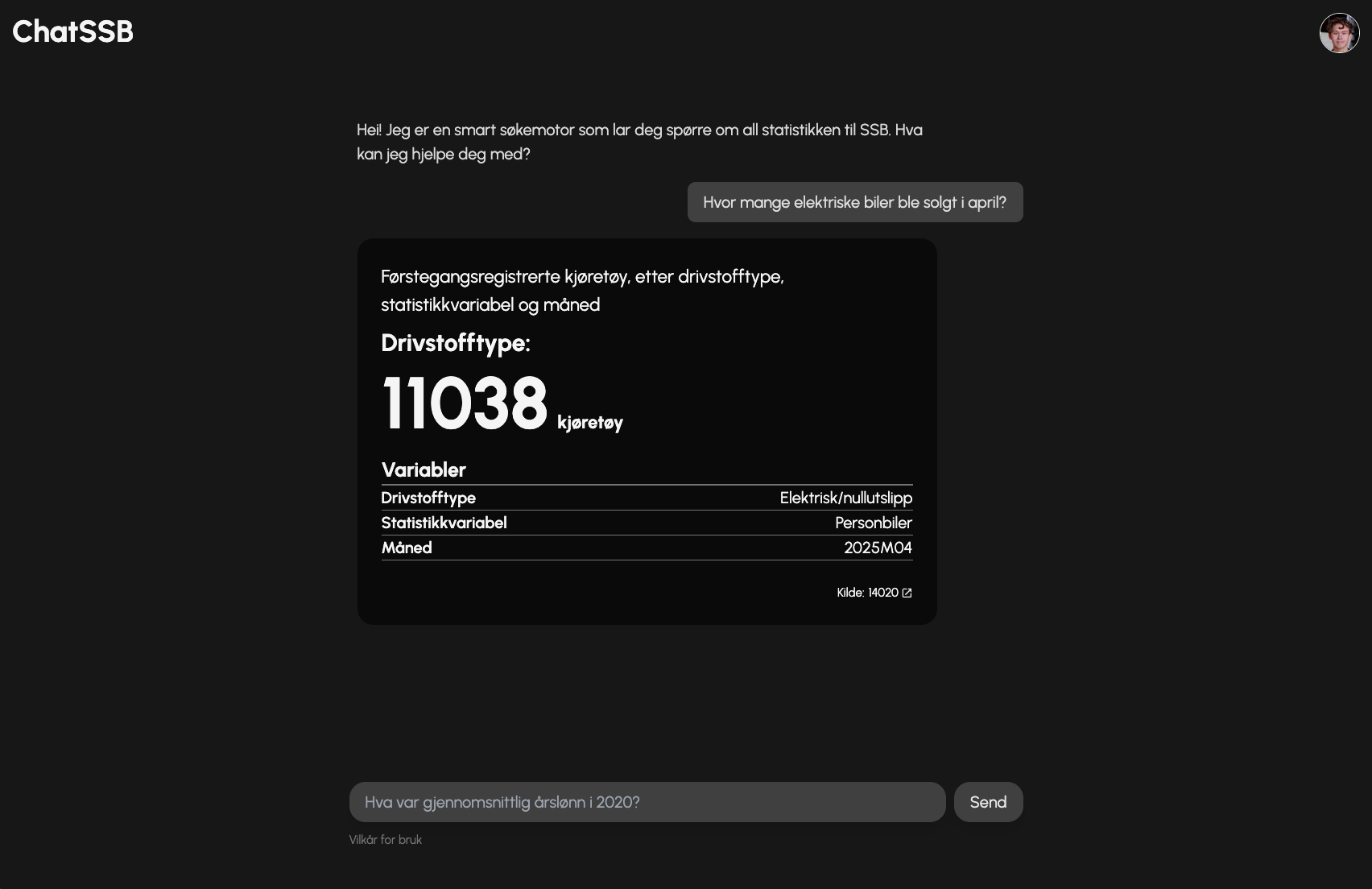
Der en språkmodell som ChatGPT henter sin informasjon fra seg selv, og det den har blitt trent på, så henter ChatSSB sin informasjon direkte fra SSB sin statistikk-database. Språkmodellen ser ikke statistikkverdiene, kun navnet og beskrivelsen på en tabell. Deretter velger den en relevant tabell basert på din forespørsel, og systemet (uten hjelp fra språkmodellen) laster inn statistikken fra denne tabellen, og viser den frem til brukeren.
Dette forsikrer at dataene du blir presentert er umulige å modifisere av språkmodellen, og at du dermed alltid får reell statistikk fra SSB. Når du blir presentert med statistikken, vil den alltid ha en 5 sifret kode vist på svaret. Dette er referansen til tabellen i SSB sin database, slik at du kan gå inn og verifisere informasjonen selv.
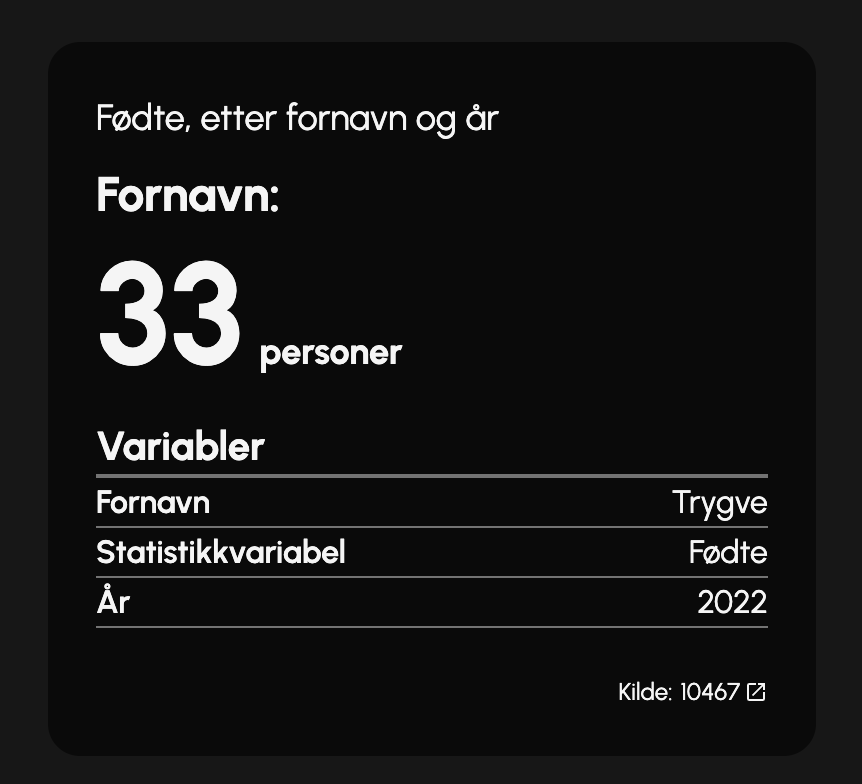
Når du mottar en statistikk-tabell, vil du også alltid bli presentert med tittelen på tabellen, slik at du alltid er sikker på om informasjonen du har blitt presentert, er relevant til det du spurte om. Denne måten å utvikle applikasjonen på gir flere fordeler, som blant annet at vi alltid har like fersk statistikk som SSB selv, uten at vi trenger å trene opp en egen språkmodell med all statistikken. Sekundet du kan finne nyutgitt statistikk på SSB, kan du også finne det på ChatSSB.
Ingen subjektive tolkninger
Det er også viktig å påpeke at der en vanlig språkmodell vil kunne snakke og uttrykke seg rundt et potensielt svar, så har ChatSSB ingen mulighet til å kommunisere med brukeren, utenfor å presentere tabeller med statistikk.
chatssb.no